*에이전트 지향 문제 해결(Agent-Oriented Problem Solving)의 정의
멀티 에이전트 시스템의 정의
상호작용하는 환경에 위치한 문제 해결사들로 구성된 컴퓨터 프로그램
유연하고 자율적이면서도 사회적으로 조직화된 행동이 가능
미리 정해진 목표나 목적을 향해 간접적으로 작동할 수 있지만, 반드시 그럴 필요는 없음
지능형 에이전트 시스템의 4가지 기준
situated (상황적)
autonomous (자율적)
flexible (유연한)
social (사회적)
*에이전트 기반 및 분산 문제 해결 주요 연구 동향
DAI(분산 인공지능) 커뮤니티
1980년 MIT에서 다중 문제 해결기로 구성된 시스템을 통한 지능적 문제 해결에 대해 논의했습니다
MIT의 Rodney Brooks 그룹의 연구
지능적 문제 해결은 중앙 집중식 지식 저장소와 범용 추론 체계가 필요하지 않다는 것을 입증
이는 분산형 및 협력적 지능 모델의 개념으로 발전
핵심 통찰
지능은 특정 작업의 맥락에서 상황화되고 활성화됨
문제 해결 과정의 일부를 환경 자체에 오프로드할 수 있음을 제시
BBN은 다양한 방식으로 배울 수 있습니다. 두 가지 기본 접근 방식이 있습니다:
네트워크 구조를 알고 있다고 가정해 보겠습니다: 각 변수에 대한 조건부 확률을 추정할 수 있습니다 데이터에서. 구조의 일부를 알고 있지만 일부 변수가 누락되었다고 가정해 보겠습니다: 이것은 마치 신경망에서 숨겨진 단위를 배우는 것과 같습니다. 경사 상승법을 사용하여 BBN을 훈련할 수 있습니다. 아무것도 알려지지 않았다고 가정해 보겠습니다. 우리는 다음을 통해 구조와 조건부 확률을 배울 수 있습니다 가능한 네트워크의 공간에서.
*1976년 앨런 뉴웰(Allen Newell)과 허버트 사이먼(Herbert A. Simon)이 튜링상 수상 강연에서 했던 내용 문제 해결 과정: 기호 시스템은 문제와 문제 공간이 주어졌을 때, 제한된 처리 자원을 사용하여 가능한 해결책을 하나씩 생성해 나갑니다. 이 과정은 해결책이 문제를 정의하는 테스트를 만족시킬 때까지 계속됩니다.
생성 순서의 중요성(100% x): 만약 기호 시스템이 잠재적인 해결책을 생성하는 순서를 통제할 수 있다면, 실제 해결책이 더 빨리 나타날 가능성이 높은 순서로 배열하는 것이 바람직합니다.
지능의 정의: 기호 시스템이 이 과정을 성공적으로 수행할 수 있다면, 그 시스템은 지능을 발휘한다고 할 수 있습니다. 즉, 제한된 처리 자원을 가진 시스템에서 지능은 다음에 무엇을 해야 할지 현명한 선택을 하는 능력에 달려 있습니다.
정의와 목적:휴리스틱은 최적의 해결책을 보장하지는 않지만, 즉각적인 목표 달성에 충분한 실용적인 문제 해결 접근 방식입니다. 이는 의사 결정의 인지적 부담을 줄이고 더 빠른 문제 해결을 가능하게 합니다.
다양한 분야에서의 응용휴리스틱은 여러 분야에서 활용됩니다:
인지심리학: 불확실성 하에서의 의사 결정에 사용되는 정신적 지름길로 연구됩니다.
인공지능: AI와 컴퓨터 과학에서 최적의 해결책을 더 효율적으로 찾기 위해 사용됩니다.
경제학: 행동경제학에서는 경제적 행동에서의 비합리적 의사 결정을 설명하는 데 휴리스틱을 활용합니다.
상태 공간 탐색에서의 정의상태 공간 탐색에서 휴리스틱은 수용 가능한 문제 해결책으로 이어질 가능성이 가장 높은 상태 공간의 가지를 선택하는 규칙으로 공식화됩니다. 이는 현재 상태가 목표 상태에 얼마나 "가까운지"를 추정하여 탐색 과정을 더 효율적으로 안내합니다.
탐색 전략의 유형
비정보 탐색: 너비 우선 탐색(BFS)이나 깊이 우선 탐색(DFS)과 같은 방법은 휴리스틱을 사용하지 않고 상태 공간을 탐색합니다.
정보 탐색: A* 알고리즘과 같은 방법은 휴리스틱을 사용하여 어떤 상태가 더 유망한지 평가하고, 탐색해야 할 노드의 수를 크게 줄입니다.
장점과 과제
효율성: 휴리스틱은 유망한 경로에 집중함으로써 탐색 알고리즘의 효율성을 크게 향상시킬 수 있습니다.
최적성: 휴리스틱이 탐색 과정을 가속화할 수 있지만, 항상 최적의 해결책으로 이어지지는 않을 수 있습니다.
계산 복잡성: 휴리스틱은 복잡한 문제 영역에서 흔히 발생하는 상태 공간 폭발 문제를 완화하는 데 도움을 줍니다.
휴리스틱은 완벽함을 추구하기보다는 실용성과 효율성에 중점을 둔 문제 해결 방법으로, 다음과 같은 특징을 가집니다:
1. 실용성 중심 - 휴리스틱은 '완벽한' 해결책보다는 '충분히 좋은' 해결책을 찾는 데 중점을 둡니다. 이는 현실 세계의 많은 문제들이 시간이나 자원의 제약 때문에 최적의 해결책을 찾기 어렵다는 점을 고려한 접근 방식입니다
.2. 신속한 의사 결정 -휴리스틱은 복잡한 상황에서 빠르게 판단하고 결정을 내릴 수 있게 해줍니다. 이는 특히 시간이 중요한 상황에서 유용합니다.
3. 인지적 부담 감소 -휴리스틱은 문제 해결 과정에서 고려해야 할 요소들을 줄여줍니다. 이를 통해 의사 결정자는 모든 가능한 선택지를 철저히 분석하는 대신, 중요한 몇 가지 요소에 집중할 수 있습니다.
4. 효율성 증대 -완벽한 해결책을 찾는 데 많은 시간과 자원을 투자하는 대신, 휴리스틱은 합리적인 시간 내에 수용 가능한 해결책을 제공합니다. 이는 전체적인 문제 해결 과정의 효율성을 높입니다.
5. 유연성 -휴리스틱은 다양한 상황에 적용할 수 있는 유연한 접근 방식입니다. 정확한 알고리즘이 없거나 적용하기 어려운 상황에서도 사용할 수 있습니다.
6. 경험과 직관의 활용 -휴리스틱은 종종 경험이나 직관에 기반합니다. 이는 전문가의 지식이나 과거의 경험을 문제 해결에 효과적으로 활용할 수 있게 해줍니다.
휴리스틱의 한계와 특성
휴리스틱은 문제 해결을 위한 유용한 도구이지만, 완벽한 방법은 아닙니다. 다음은 휴리스틱의 주요 한계와 특성입니다:
1. 오류 가능성 -휴리스틱은 모든 발견과 발명의 규칙과 마찬가지로 오류를 범할 수 있습니다. 이는 휴리스틱이 완벽한 해결책을 보장하지 않음을 의미합니다
2. 추측에 기반한 접근 -휴리스틱은 문제 해결 과정에서 다음 단계에 대한 '정보에 기반한 추측'에 불과합니다. 이는 휴리스틱이 항상 최적의 경로를 제시하지는 않을 수 있음을 의미합니다.
3. 예측의 한계 -휴리스틱은 탐색 과정에서 더 먼 단계의 상태 공간의 정확한 동작을 예측하는 데 한계가 있습니다. 이는 복잡한 문제에서 장기적인 결과를 정확히 예측하기 어려울 수 있음을 의미합니다.
4. 제한된 정보 사용 -휴리스틱은 제한된 정보만을 사용하기 때문에 위와 같은 한계를 가집니다. 모든 가능한 정보를 고려하지 않고 일부 정보만을 선택적으로 사용하여 판단을 내립니다.
휴리스틱의 의의
이러한 한계에도 불구하고 휴리스틱은 여전히 중요한 문제 해결 도구입니다:
효율성: 복잡한 문제에 대해 빠르게 대응할 수 있게 해줍니다.
실용성: 완벽한 해결책을 찾는 것이 불가능하거나 비실용적인 상황에서 유용합니다.
적응성: 새로운 상황에 빠르게 적응할 수 있게 해줍니다.
인지 부하 감소( 불확실성 처리 ): 의사 결정 과정에서 고려해야 할 요소를 줄여줍니다.
계산 복잡성 감소: 모든 가능성을 탐색하는 대신, 유망한 해결책에 집중함으로써 계산 복잡성을 줄일 수 있습니다
인간의 문제 해결 방식 모방: 휴리스틱은 인간 전문가의 사고 과정을 모방하여, 보다 자연스럽고 이해하기 쉬운 AI 시스템을 만들 수 있습니다.
*Dynamic Programming
Best-First Search와 Hill Climbing은 휴리스틱 탐색 알고리즘의 대표적인 예시
Best-First Search 구현
Best-First Search는 휴리스틱 정보를 활용하여 더 효율적인 탐색을 수행하는 알고리즘입니다. 주요 특징은 다음과 같습니다:
오픈 리스트(Open List) 사용
현재 탐색의 경계(fringe)를 추적하는 데 사용됩니다.
아직 탐색하지 않은 노드들을 저장합니다.
우선순위 큐로 구현되어 가장 유망한 노드를 빠르게 선택할 수 있습니다.
클로즈드 리스트(Closed List) 사용
이미 방문한 상태(노드)를 기록합니다.
중복 탐색을 방지하고 순환을 피하는 데 도움이 됩니
Best-First Search는 다음과 같이 구현할 수 있습니다:
우선순위 큐 사용: 탐색할 노드들을 휴리스틱 값에 따라 정렬된 우선순위 큐에 저장합니다.
노드 확장: 우선순위 큐에서 가장 유망한(휴리스틱 값이 가장 좋은) 노드를 선택하여 확장합니다.
자식 노드 평가: 확장된 노드의 모든 자식 노드를 생성하고 각각의 휴리스틱 값을 계산합니다.
큐 업데이트: 생성된 자식 노드들을 우선순위 큐에 추가합니다.
반복: 목표 상태에 도달하거나 더 이상 탐색할 노드가 없을 때까지 2-4 단계를 반복합니다.
Hill Climbing 구현
Hill Climbing은 Best-First Search의 간소화된 버전으로, 다음과 같이 구현할 수 있습니다:
현재 노드 확장: 현재 노드의 자식 노드들을 생성합니다.
최선의 자식 선택: 자식 노드들 중 가장 좋은 휴리스틱 값을 가진 노드를 선택합니다.
이동: 선택된 자식 노드로 이동합니다. 이때 다른 자식 노드들과 부모 노드는 버립니다.
반복: 더 이상 개선이 없을 때까지 1-3 단계를 반복합니다.
Hill-Climbing의 주요 문제점
잘못된 휴리스틱으로 인한무한 경로
부적절한 휴리스틱함수는 알고리즘을 목표와 무관한 방향으로 계속 이동하게 할 수 있습니다.
이는 해결책을 찾지 못하고 무한히탐색을 계속하는 결과를 초래할 수 있습니다.
이력 관리 부재
Hill-Climbing은 현재 상태만을 고려하고이전 상태의 정보를 저장하지 않습니다.
이로 인해 잘못된 경로에 빠졌을 때 이전 상태로돌아가 다른 경로를 탐색하는 것이 불가능합니다.
지역 최적해(Local Maxima) 문제
알고리즘이 전역 최적해(Global Optimum)가 아닌 지역 최적해에 도달하면 더 이상 개선할 수 없어멈추게 됩니다.
이는 더 나은 해결책이 존재함에도 불구하고 탐색을 중단하는 결과를 낳습니다.
성능 개선 방법
교란(Perturbation)
현재 상태에 작은 무작위 변화를 주어 지역 최적해에서 벗어나려는 시도입니다.
이는 Simulated Annealing과 같은 더 복잡한 알고리즘의 기본 아이디어가 됩니다.
Random Restart
여러 번의 무작위 초기점에서 Hill-Climbing을 실행하는 방법입니다.
이는 다양한 지역 최적해를 탐색할 수 있게 해주지만, 여전히 전역 최적해를 보장하지는 않습니다.
Beam Search
여러 개의 상태를 동시에 탐색하여 지역 최적해에 빠질 가능성을 줄입니다.
주요 특징
단순성: Hill Climbing은 Best-First Search보다 구현이 더 간단합니다. 메모리 사용량도 적습니다.
지역 최적해: Hill Climbing은 지역 최적해에 빠질 수 있습니다. 반면 Best-First Search는 더 넓은 탐색을 수행합니다.
메모리 사용: Best-First Search는 탐색 과정에서 많은 노드를 메모리에 저장해야 할 수 있습니다. Hill Climbing은 현재 노드만 기억하면 됩니다.
완전성: Best-First Search는 적절한 구현 시 완전한 알고리즘이 될 수 있습니다. Hill Climbing은 완전성을 보장하지 않습니다.
휴리스틱 의존성: 두 알고리즘 모두 휴리스틱 함수의 품질에 크게 의존합니다. 좋은 휴리스틱은 탐색 효율을 크게 향상시킬 수 있습니다.
좋은 휴리스틱을 설계하는 것은 어려운 경험적 문제입니다. 주요 포인트는 다음과 같습니다:
휴리스틱 설계의 어려움
위의 예시들은 좋은 휴리스틱을 고안하는 것이 쉽지 않음을 보여줍니다.
단일 상태 정보만으로 지능적인 선택을 하는 것이 목표이지만, 이는 도전적인 작업입니다.
휴리스틱 설계의 목표
제한된 정보(단일 상태 정보)를 사용하여 지능적인 선택을 하는 것입니다.
완전한 정보가 없는 상황에서 최선의 추정을 해야 합니다.
좋은 휴리스틱의 특성
계산이 빠르고 효율적이어야 합니다.
목표 상태까지의 실제 비용을 잘 추정해야 합니다.
문제의 특성을 잘 반영해야 합니다.
경험적 접근 방식
휴리스틱 설계는 주로 경험적 문제입니다.
직관과 판단이 도움이 되지만, 충분하지 않습니다.
성능 평가의 중요성
휴리스틱의 최종 평가 기준은 실제 문제 인스턴스에서의 성능입니다.
이론적으로 좋아 보이는 휴리스틱도 실제 성능이 좋지 않을 수 있습니다.
반복적 개선
초기 휴리스틱을 설계한 후 실제 성능을 분석하고 개선하는 과정이 필요합니다.
다양한 문제 인스턴스에 대해 테스트하고 결과를 분석해야 합니다.
도메인 지식의 활용
문제 도메인에 대한 깊은 이해가 좋은 휴리스틱 설계에 도움이 됩니다.
도메인 전문가의 인사이트를 활용하는 것이 유용할 수 있습니다.
휴리스틱 탐색과 전문가 시스템의 관계에 대해 정리해 드리겠습니다:
전문가 시스템에서의 휴리스틱 구현
신뢰도 측정(confidence measures)을 사용하여 규칙의 결과를 평가합니다
성공 가능성이 가장 높은 결론을 선택하기 위해 신뢰도를 활용합니다.
매우 낮은 신뢰도를 가진 상태는 완전히 제거될 수 있습니다.
간단한 게임(예: 8-퍼즐)을 사용하는 이유
탐색 공간이 휴리스틱 가지치기가 필요할 만큼 충분히 크습니다.
대부분의 게임은 다양한 휴리스틱 평가를 비교하고 분석할 수 있을 만큼 복잡합니다.
게임은 일반적으로 복잡한 표현 문제를 포함하지 않습니다.
단일 휴리스틱을 전체 탐색 공간에 적용할 수 있습니다.
현실적인 문제로의 확장
더 현실적인 문제는 휴리스틱 탐색의 구현과 분석을 크게 복잡하게 만듭니다.
그러나 간단한 게임에서 얻은 통찰력은 전문가 시스템 응용 프로그램과 같은 문제로 일반화될 수 있습니다.
현실 문제에서는 단일 휴리스틱이 모든 상태에 적용되지 않을 수 있습니다.
각 규칙은 특정 경우에 적용될 수 있는 휴리스틱으로 볼 수 있습니다.
패턴 매처(pattern matcher)가 적절한 규칙(휴리스틱)을 관련 상태와 매칭시킵니다
전문가 시스템에서의 휴리스틱 적용
전문가 시스템은 주로 if-then 규칙을 사용하여 지식을 표현합니다
추론 엔진은 현재 지식 베이스의 상태를 평가하고, 관련 규칙을 적용하여 새로운 지식을 추론합니다
전진 추론(forward chaining)과 후진 추론(backward chaining)을 사용하여 결론을 도출합니다
휴리스틱의 한계와 도전
지식 베이스의 크기가 증가함에 따라 처리 복잡성이 증가합니다
규칙 간의 일관성 검증이 어려워집니다
규칙의 우선순위 설정과 모호성 해결이 필요합니다
휴리스틱 평가의 장단점
장점: 빠르고 비용 효율적인 방법으로 사용성 문제를 식별할 수 있습니다
단점: 주관적이며 실제 사용자의 특정 요구를 완전히 반영하지 못할 수 있습니다
휴리스틱 함수의 세 가지 중요한 특성인 허용성(Admissibility), 단조성(Monotonicity), 정보성(Informedness)에 대해 설명드리겠습니다.
허용성 (Admissibility)
허용성은 휴리스틱 함수가 목표 상태까지의 실제 비용을 절대 과대평가하지 않는 특성을 말합니다.
정의: 모든 노드 n에 대해 h(n) ≤ h*(n)이 성립해야 합니다. 여기서 h(n)은 휴리스틱 추정치이고, h*(n)은 실제 최적 비용입니다
장점:
최적 해를 보장합니다.
A* 알고리즘과 같은 탐색 알고리즘의 최적성을 보장합니다
허용성의 중요성
최적해 보장: 허용적인 알고리즘은 항상 최적의 해결책을 찾습니다.
완전성: 해가 존재한다면 반드시 찾아냅니다.
효율성: 불필요한 탐색을 줄일 수 있습니다.
예시: 8-퍼즐 문제에서 "제자리에 있지 않은 타일의 수"를 휴리스틱으로 사용하는 경우, 이는 허용적입니다
단조성 (Monotonicity)
단조성은 휴리스틱 함수가 로컬하게 일관성을 유지하는 특성을 말합니다.
정의: 모든 노드 n과 그의 후속 노드 n'에 대해 h(n) ≤ cost(n, n') + h(n')가 성립해야 합니다
특징:
경로를 따라 f 값(g+h)이 절대 감소하지 않습니다.
각 상태에 도달할 때 최소의 g(n) 값을 가집니다
단조성의 특징
지역적 허용성: 탐색 중만나는 각 상태에 대해 일관되게 최소 경로를찾습니다.
경로 재검사 불필요: 최선 우선 탐색에서 새 경로가 더짧은지 확인할 필요가 없습니다.
f 값의 단조 증가: f(n) = g(n) + h(n)이 경로를 따라 단조증가합니다.
허용성 보장: 모든 단조적 휴리스틱은 허용적입니다.
단조성의 장점
효율성: 노드 재방문이 불필요하여 탐색 효율이 높아집니다.
일관성: 탐색 과정에서 일관된 결과를 제공합니다.
구현 용이성: 알고리즘 구현이 더 간단해집니다.
장점: A* 알고리즘의 효율성을 높이며, 이미 방문한 노드를 다시 고려할 필요가 없게 합니다
정보성 (Informedness)
정보성은 휴리스틱 함수가 얼마나 정확하고 유용한 정보를 제공하는지를 나타냅니다.
정의: 더 정보적인 휴리스틱은 목표까지의 실제 비용에 더 가까운 추정치를 제공합니다
특징:
더 정보적인 휴리스틱은 탐색 공간을 더 효과적으로 줄일 수 있습니다.
최적 경로 주변으로 탐색을 더 집중시킵니다
트레이드오프: 정보성이 높을수록 계산 비용이 증가할 수 있습니다.
결론
허용성은 최적해를 보장하지만, 때로는 비효율적일 수 있습니다.
단조성은 알고리즘의 효율성을 높이며, 모든 단조적 휴리스틱은 허용적입니다
정보성은 탐색 효율성을 높이지만, 계산 비용과의 균형을 고려해야 합니다.
복잡성 문제와 관련된 주요 개념들에 대해 자세히 설명드리겠습니다.
1. 분기 계수 (Branching Factor)
정의: 탐색 공간에서 각 상태에서 평균적으로 생성되는 후속 상태의 수공식: T = B + B² + B³ + ... + Bᴸ = B(Bᴸ - 1) / (B - 1)
B: 분기 계수
L: 경로 길이
T: 전체 탐색 상태 수
의미:
분기 계수가 크면 탐색 공간이 급격히 증가합니다.
효율적인 탐색을 위해 분기 계수를 줄이는 것이 중요합니다.
2. Open 및 Closed 리스트의 크기
Open 리스트: 아직 탐색하지 않은 노드들의 집합 Closed 리스트: 이미 탐색한 노드들의 집합관리 방법:
선택적 저장: Open 리스트에 가장 유망한 상태만 저장
장점: 더 집중된 탐색 가능
단점: 최적 해 또는 유일한 해결책을 놓칠 위험
빔 탐색 (Beam Search):
정의: Open 리스트의 크기에 제한을 두는 기법
작동 방식: 각 레벨에서 가장 유망한 k개의 노드만 유지
장점: 메모리 사용량 감소, 탐색 속도 향상
단점: 최적해를 놓칠 가능성 존재
3. 정보성 (Informedness)
정의: 휴리스틱 함수가 제공하는 정보의 질과 양특징:
탐색 효율성: 더 정보적인 휴리스틱일수록 탐색해야 할 공간이 줄어듭니다.
계산 비용: 추가 정보를 얻기 위한 계산 비용이 증가할 수 있습니다.
트레이드오프:
정보성 증가 → 탐색 공간 감소 → 전체 탐색 시간 감소
정보성 증가 → 휴리스틱 계산 비용 증가 → 노드당 처리 시간 증가
최적화 전략:
간단하고 빠른 휴리스틱 사용: 큰 탐색 공간, 빠른 노드 평가
복잡하고 정확한 휴리스틱 사용: 작은 탐색 공간, 느린 노드 평가
알파-베타 가지치기(Alpha-Beta Pruning) 절차에 대해 상세히 설명드리겠습니다.
기존 미니맥스 알고리즘의 한계
두 번의 분석 필요:
첫 번째: 지정된 깊이까지 내려가 휴리스틱 적용
두 번째: 값을 트리 위로 전파
비효율성: 모든 노드를 평가해야 함
알파-베타 가지치기의 개선사항
탐색과 평가의 결합:
깊이 우선 탐색(DFS) 방식으로 진행
탐색 중 알파와 베타 값 생성 및 갱신
알파와 베타 값의 특성:
알파(α): MAX 플레이어의 최소 보장 점수, 증가만 함
베타(β): MIN 플레이어의 최대 허용 점수, 감소만 함
탐색 종료 규칙
MIN 노드에서의 종료:
조건: β ≤ α (조상 MAX 노드의 알파 값)
의미: 이 경로는 MAX에게 이미 보장된 값보다 나쁨
MAX 노드에서의 종료:
조건: α ≥ β (조상 MIN 노드의 베타 값)
의미: 이 경로는 MIN에게 이미 허용된 값보다 나쁨
알고리즘 진행 과정
초기화:
α = -∞, β = +∞로 시작
깊이 우선 탐색:
리프 노드까지 내려가며 α, β 갱신
가지치기:
종료 규칙 만족 시 해당 가지 탐색 중단
값 전파:
MAX 레벨: α = max(α, 자식 노드 값)
MIN 레벨: β = min(β, 자식 노드 값)
최종 선택:
루트에서 가장 높은 α 값을 가진 움직임 선택
장점
효율성: 불필요한 노드 평가 제거
깊은 탐색: 같은 시간에 더 깊은 탐색 가능
최적해 보장: 미니맥스와 동일한 결과 도출
주의사항
노드 순서: 좋은 움직임을 먼저 평가할수록 효과적
초기 추정: 정확한 초기 α, β 값이 중요
결론
알파-베타 가지치기는 미니맥스 알고리즘의 효율성을 크게 개선합니다. 탐색과 평가를 결합하고, α와 β 값을 이용해 불필요한 탐색을 줄임으로써, 더 깊은 탐색을 가능하게 합니다. 이는 체스나 오셀로 같은 복잡한 게임에서 강력한 AI 플레이어를 만드는 데 핵심적인 역할을 합니다.
복잡성 문제 해결 방안
휴리스틱 함수 개선:
더 정확하고 정보적인 휴리스틱 설계
도메인 지식 활용
탐색 알고리즘 최적화:
알파-베타 가지치기 사용
반복 깊이 증가(Iterative Deepening) 적용
메모리 관리:
트랜스포지션 테이블 사용
선택적 노드 저장
병렬화:
다중 코어/GPU 활용
분산 컴퓨팅 적용
근사 해법:
몬테카를로 트리 탐색 사용
유전 알고리즘 적용
GAME 설명------------------------------------------------------------------------------------------------------------------------------------------------
알파-베타 가지치기는 미니맥스 알고리즘을 최적화한 방법입니다. 이 알고리즘의 주요 목적은 게임 트리 탐색 시 불필요한 노드 탐색을 줄여 계산 효율성을 높이는 것입니다.알고리즘의 주요 특징은 다음과 같습니다:
알파(α)와 베타(β) 값 사용:
알파는 최대화 플레이어가 보장할 수 있는 최소 점수
베타는 최소화 플레이어가 보장할 수 있는 최대 점수
가지치기:
알파 ≥ 베타일 때 더 이상의 탐색이 무의미하므로 해당 가지를 제거
깊이 우선 탐색:
트리를 깊이 우선으로 탐색하며 알파와 베타 값을 갱신
최적화:
불필요한 노드 탐색을 줄여 계산 시간과 메모리 사용을 크게 줄임
미니맥스 알고리즘은 완전 탐색 가능한 그래프에서 2인용 게임의 최적 전략을 찾는 데 사용되는 중요한 알고리즘입니다. 이에 대해 자세히 설명드리겠습니다.
미니맥스 알고리즘의 개요
목적: 적대적이고 예측 불가능한 상대방이 존재하는 2인용 게임에서 최적의 움직임을 결정합니다.
적용 범위: 상태 공간이 충분히 작아 완전 탐색이 가능한 게임에 적합합니다.
기본 원리: 한 플레이어는 점수를 최대화(MAX)하려 하고, 다른 플레이어는 최소화(MIN)하려 합니다.
알고리즘 작동 방식
게임 트리 생성: 현재 상태에서 가능한 모든 움직임과 그 결과를 트리 형태로 표현합니다.
말단 노드 평가: 게임의 종료 상태에 도달하면 해당 상태의 점수를 계산합니다.
값 역전파:
MAX 레벨: 자식 노드 중 최대값 선택
MIN 레벨: 자식 노드 중 최소값 선택
루트까지 반복: 이 과정을 루트 노드까지 반복하여 각 움직임의 최종 평가 값을 결정합니다.
1.패킷 헤더 크기가 매우 큰 경우 예상할 수 있는 문제점은 무엇인가요?
패킷 구성:
일반적으로 패킷(세그먼트, 프레임 포함)은 헤더와 페이로드로 구성됩니다.
헤더는 해당 계층의 제어 정보를 포함하고, 페이로드는 상위 계층에서 전달된 데이터를 포함합니다.
효율성 감소: 큰 헤더는 실제 데이터에 사용할 수 있는 공간을 줄여 전송 효율을 낮춥니다.
지연 증가: 각 네트워크 홉에서 처리 시간이 증가하여 지연이 커질 수 있습니다.
대역폭 사용 증가: 헤더가 페이로드보다 더 많은 대역폭을 소비하여 비용이 증가하고 비효율적
2.패킷에 헤더가 없으면 어떻게 되나요?
제어 정보 부족: 헤더가 없으면 출발지 및 목적지 주소와 같은 필수 제어 정보가 없어 네트워크를
통해 라우팅할 수 없습니다.
데이터 손실 가능성: 라우터와 스위치는 트래픽을 관리하기 위해 헤더 정보를 사용하므로,
헤더가 없으면 패킷이 잘못 라우팅되거나 손실될 수 있습니다.
3.손실된 패킷을 재전송하는 방법
타임아웃 기반 재전송:
패킷이 전송되고 나면, 송신자는 수신자로부터 확인 응답(ACK)을 기다립니다.
일정 시간 내에 ACK가 수신되지 않으면 송신자는 해당 패킷이 손실되었다고 판단하고 재전송
빠른 재전송:
수신자가 동일한 패킷에 대한 중복 ACK를 세 번 받으면, 송신자는 해당 패킷이 손실되었다고
가정하고 즉시 재전송합니다. 이는 타임아웃을 기다리지 않고 빠르게 손실된 패킷을 복구
4.TCP와 달리 UDP는 신뢰성 메커니즘을 제공하지 않지만, 여전히 인터넷에서 사용됩니다.
왜 사람들이 UDP를 사용할까요?
실시간 상호작용: 지연에 민감한 서비스에 적합합니다.
중복성을 포함하는 애플리케이션: 손실에 강한 애플리케이션에서 사용됩니다
5. 인터넷 서비스가 느려지는 원인
너무 많은 소스가 네트워크가 처리할 수 있는 것보다 너무 빠르게 많은 데이터를 전송할 때 발생
구체적으로, 트래픽 양이 링크 대역폭을 초과하면 큐가 쌓이고 지연이 증가하게 됩니다.
-노드 처리 지연 (Nodal Processing Delay)
-큐잉 지연 (Queuing Delay)
-전송 지연 (Transmission Delay)
-전파 지연 (Propagation Delay)
*캡슐화(Encapsulation) : 데이터가 네트워크를 통해 안전하고 정확하게 전달되도록 보장
출발지(Source):
데이터가 애플리케이션 계층에서 시작되어 각 계층을 거치면서 헤더가 추가됩니다.
각 계층은 다음과 같은 헤더를 추가합니다:
애플리케이션: 메시지(M)
전송(Transport): 세그먼트(Segment) 헤더(Ht)
네트워크(Network): 데이터그램(Datagram) 헤더(Hn)
링크(Link): 프레임(Frame) 헤더(H1)
스위치와 라우터:
스위치에서는 링크 계층까지의 헤더가 사용됩니다.
라우터에서는 네트워크 계층까지의 헤더가 사용됩니다.
목적지(Destination):
데이터는 목적지에 도달하면 각 계층에서 헤더를 제거하며 상위 계층으로 전달됩니다.
최종적으로 애플리케이션 계층에 도달하여 원래의 메시지(M)로 복원됩니다.
*큐잉(Queuing) - 큐잉 문제는 네트워크 혼잡의 원인
큐의 용량:
대기열(버퍼)의 이전 링크는 유한한 용량을 가지고 있습니다.
패킷 손실:
대기열이 가득 차면 도착하는 패킷은 버려집니다(손실됨).
손실된 패킷 처리:
손실된 패킷은 이전 노드, 송신자 끝 시스템에 의해 재전송되거나, 전혀 재전송되지 않을 수 있습니다.
*상태 공간 탐색(State Space Search) : 문제 해결 과정에서 상태와 상태 간의 전환을 시각화하고 분석하는 데 유용합니다.
질문에 답하기 위한 주요 도구로 사용됩니다.
문제를 상태 공간 그래프로 표현함으로써, 그래프 이론을 활용하여 문제와 이를 해결하는 절차의 구조와 복잡성을 분석할 수 있습니다.
*상태 공간 탐색 전략
데이터 기반 탐색 (Data-driven search) : 문제의 사실을 바탕으로 규칙과 합법적인 움직임을 적용하여 목표로 이어지는 새로운 사실을 생성합니다
전방 체인 (Forward Chaining): 데이터 기반 탐색은 종종 전방 체인이라고 불립니다.
시작점: 문제 해결자는 문제의 주어진 사실과 상태를 변경할 수 있는 합법적인 움직임이나 규칙의 집합으로 시작합니다.
탐색 과정: 규칙을 적용하여 새로운 사실을 생성하고, 이러한 새로운 사실을 다시 규칙에 사용하여 더 많은 사실을 생성합니다. 이 과정은 목표 조건을 만족하는 경로를 생성할 때까지 계속됩니다.
적합한 상황
문제의 초기 진술에서 모든 데이터 또는 대부분의 데이터가 주어졌을 때.
잠재적인 목표가 많지만, 특정 문제 상황에서 사실과 주어진 정보를 사용할 수 있는 방법이 몇 가지뿐일 때.
목표나 가설을 설정하기 어려울 때 (예: DENDRAL).
탐색 방식
문제의 주어진 데이터에서 발견된 지식과 제약 조건을 사용하여, 참으로 알려진 선을 따라 탐색을 안내합니다.
목표 기반 탐색(Goal-driven search) : 목표에 초점을 맞추고, 목표를 생성할 수 있는 규칙을 찾아서 문제의 주어진 사실로 이어지는 규칙과 하위 목표를 통해 역방향으로 연결합니다.
목표 설정: 해결하려는 목표를 설정합니다.
규칙 확인: 이 목표를 생성할 수 있는 규칙이나 합법적인 움직임을 확인합니다.
조건 결정: 이러한 규칙을 사용하기 위해 어떤 조건이 참이어야 하는지를 결정합니다.
하위 목표 설정: 이러한 조건들은 새로운 목표 또는 하위 목표가 됩니다.
탐색 과정: 하위 목표를 통해 문제의 사실로 되돌아갈 때까지 역방향으로 탐색을 계속합니다. 이는 데이터에서 목표로 이어지는 움직임이나 규칙의 체인을 찾지만, 반대 순서로 진행됩니다.
다른 이름: 목표 기반 추론 또는 역방향 체인이라고도 불립니다.
제안 조건
문제 진술에서 목표나 가설이 주어졌거나 쉽게 설정할 수 있을 때.
문제의 사실과 일치하는 많은 규칙이 있어 결론이나 목표의 수가 증가할 때.
문제 데이터가 주어지지 않고 문제 해결자가 직접 획득해야 할 때.
탐색 방식
원하는 목표에 대한 지식을 사용하여 관련 규칙을 통해 탐색을 안내하고, 불필요한 가지를 제거합니다.
*오일러 경로(Euler Path)
오일러의 관찰:
그래프에 홀수 차수를 가진 노드가 정확히 0개 또는 2개 있어야만 경로가 가능하다고 했습니다. 그렇지 않으면 경로는 불가능합니다.
쾨니히스베르크 문제:
오일러 경로 찾기 문제로 연결됩니다.
술어 논리 표현:
노드의 차수 개념을 제시하지 않습니다.
그래프 이론의 힘:
객체, 속성, 관계의 구조를 분석하는 데 사용됩니다.
*그래프 이론(오일러에 의해 발견)(방향이 있는 그래프)
시작 노드(rooted grpah = unique node)
노드 집합: 문제 해결 과정의 개별 상태를 나타냅니다(유한할 필요 x, 노드가 2개 이상 있어야 아크존재),
중복되는 노드가 있다면 loop or cycle
아크 또는 링크 집합: 노드 쌍을 연결하며, 상태 간의 전환을 나타냅니다.
방향이 없는 그래프 undirected graph
상태 공간 모델:
노드: 문제 해결 과정에서의 이산 상태를 의미합니다. 이는 논리적 추론의 결과나 게임 보드의 구성을 포함할 수 있습니다.
아크: 상태 간 전환을 나타내며, 논리적 추론이나 게임의 합법적인 움직임을 포함할 수 있습니다.
*Implementing Graph Search(상태 공간 그래프를 통해 시작 상태에서 목표로 가는 경로를 찾아야 합니다)
-Backtracking : 모든 경로를 체계적으로 시도하는 기술,추적 검색은 시작 상태에서 시작하여 목표 또는 "막다른 골목"에 도달할 때까지 경로를 추적합니다
-SL : 주 목록의 경우는 현재 시도 중인 경로의 상태를 나열합니다. 목표가 발견되면 SL은 솔루션 경로의 순서대로 나열된 상태 목록을 포함합니다
-NSL : 새 주 목록의 경우는 평가를 기다리는 노드, 즉 아직 생성 및 검색되지 않은 하위 노드를 포함합니다.(나중에 검색될 후보들 포함)
-DE : 또는 막다른 골목는 후손이 목표 노드를 포함하지 않은 상태를 나열합니다. 이러한 상태가 다시 발생하면 DE의 요소로 감지되어 즉시 고려 대상에서 제외됩니다.(나중에 갈 곳에서 제외)
-Backtrack : 스타트에서 시작해서 목표을 만날때까지 진행
-depth-first : 모든 자녀와 그 후손은 형제자매보다 먼저 검사를 받습니다(B^n)
-시작 상태에서 목표까지 최단 경로를 찾을 수 있습니다(최단 경로 보장)
-후손이 많아질수록 조합론 증가(복잡도 증가)
-메모리 낭비 O
-breadth-first : 동등한 레벨을 먼저 검사하고 후손을 검사(B*n)
-상태가 처음 발견되었을 때 상태로 가는 최단 경로를 찾을 수 있다는 보장은 없습니다
너비 우선 검색 알고리즘을 수정하여 만들 수 있습니다(Queue -> stack)
메모리 낭비 x
-best-first : 위에 것과 비슷하지만 가장 가능 가능성이 높은 것을 먼저 조사한다(stack과 queue가 아니다)
*하이퍼그래프:
N: 노드의 집합.
H: 하이퍼아크의 집합. 이는 다음과 같은 순서쌍으로 정의됩니다:
첫 번째 요소는 집합 N의 단일 노드입니다.
두 번째 요소는 N의 부분집합입니다.
일반 그래프는 하이퍼그래프의 특수한 경우로, 자손 노드 집합의 크기가 1인 경우를 말합니다. 즉, 일반 그래프의 간선은 정확히 두 개의 노드를 연결하지만, 하이퍼그래프에서는 하나의 간선(하이퍼아크)이 두 개 이상의 노드를 연결할 수 있습니다.
*명제 논리 (Propositional Calculus)
명제 논리의 의미론 정의
명제 집합의 해석은 각 명제 기호에 대해 참(T) 또는 거짓(F)의 진리값을 할당하는 것입니다.
기호 "true"는 항상 T로 할당되고, "false"는 F로 할당됩니다.
Satisfy (만족):
표현 S가 해석 I와 특정 변수 할당 하에서 참(T)의 값을 가지면, S는 만족된다고 합니다.
Model (모델):
해석 I가 모든 변수 할당에 대해 S를 만족시키면, I는 S의 모델이라고 합니다.
문장의 해석 또는 진리값 결정
부정 (Negation): ¬P는 P가 참이면 거짓이고, P가 거짓이면 참입니다.
합집합 (Conjunction): ∧는 두 항이 모두 참일 때만 참입니다.
교집합 (Disjunction): ∨는 두 항이 모두 거짓일 때만 거짓입니다.
함축 (Implication): →는 전제가 참이고 결론이 거짓일 때만 거짓입니다.
동치 (Equivalence): ≡는 두 표현이 모든 해석에서 동일할 때만 참입니다.
명제 논리 기호
명제 기호: P, Q, R 등
진리 기호: true, false
연결자: ∧ (그리고), ∨ (또는), ¬ (부정), → (함축), ≡ (동치)
명제 논리 문장
모든 명제 기호와 진리 기호는 문장입니다.
문장의 부정(¬)도 문장입니다.
두 문장의 합집합(∧) 또는 교집합(∨)도 문장입니다.
한 문장이 다른 문장을 함축(→)하는 것도 문장입니다.
두 문장이 동치(≡)인 것도 문장입니다.
명제 논리 문장의 정의
모든 명제 기호와 진리 기호는 문장입니다.
예: true, P, Q, R은 문장입니다.
부정 예: ¬P와 ¬false는 문장입니다.
합집합 예: P ∧ ¬P는 문장입니다.
교집합 예: P ∨ ¬P는 문장입니다.
함축 예: P → Q는 문장입니다.
동치 예: P ∨ Q ≡ R은 문장입니다.
WFFs (Well-Formed Formulas)
합법적인 문장
예시: ((P ∧ Q) → R) ≡ ¬P ∨ ¬Q ∨ R
이유: P, Q, R은 명제이고 각각 문장으로 인정됩니다. 결합, 부정, 함축, 동치 등의 연산을 통해 복잡한 문장을 형성합니다.
명제 문장의 의미 (Semantics)
정확한 의미 처리가 논리적 오류를 피하는 데 필수적입니다.
명제 기호는 세계에 대한 진술을 나타냅니다.
예시: P는 "비가 온다"를 나타낼 수 있습니다.
명제는 세계의 상태에 따라 참 또는 거짓일 수 있습니다.
진리값 할당은 "해석"이라고 불립니다.
중요한 명제 관계
이중 부정 법칙: ¬(¬P) ≡ P
드 모르간의 법칙: ¬(P ∨ Q) ≡ (¬P ∧ ¬Q) 및 ¬(P ∧ Q) ≡ (¬P ∨ ¬Q)
교환 법칙: (P ∧ Q) ≡ (Q ∧ P) 및 (P ∨ Q) ≡ (Q ∨ P)
연관 법칙: ((P ∧ Q) ∧ R) ≡ (P ∧ (Q ∧ R)) 및 ((P ∨ Q) ∨ R) ≡ (P ∨ (Q ∨ R))
분배 법칙: P ∨ (Q ∧ R) ≡ (P ∨ Q) ∧ (P ∨ R)
연산자 ∧의 진리표
P와 Q가 모두 참일 때만 P ∧ Q가 참입니다.
그 외의 경우에는 거짓입니다.
*명제 논리의 한계
개별 명제의 구성 요소에 접근할 방법이 없습니다.
각 원자 기호(P, Q 등)는 어느 정도 복잡성을 지닌 명제를 나타냅니다.
예: "화요일에 비가 왔다"는 명제
변수를 허용하지 않습니다.
*술어 논리 (Predicate Calculus)(명제 논리 + 술어 + 양화 + 추론 규칙)
구성 요소에 접근할 수 있는 방법을 제공합니다.
예: weather(tuesday, rain)
추론 규칙을 통해 술어 논리 표현을 조작하고 새로운 문장을 유도할 수 있습니다.
표현식에 변수를 포함할 수 있습니다.
예: weather(X, rain)
술어 논리 기호 (Predicate Calculus Symbols)
알파벳 구성: 대문자와 소문자, 숫자(0-9), 밑줄("_")
기호는 문자로 시작하고 합법적인 문자로 이어집니다.
예시: a, R, 6, 9, p, _, z
불법 문자: #, %, @, /, &, " "
합법적인 술어 논리 기호 예시: George, fire3, tom_and_jerry, bill, XXXX
불법 문자열 예시: 3jack, "no blanks allowed", ab%ocd
기호와 용어 (Symbols and Terms)
진리 기호 (Truth Symbols): true와 false (예약된 기호)
상수 기호 (Constant Symbols): 첫 글자가 소문자인 기호 표현 (예: george, tree)
변수 기호 (Variable Symbols): 대문자로 시작하는 기호 표현 (예: George, BILL)
함수 기호 (Function Symbols): 첫 글자가 소문자인 기호 표현
양화사 (Quantifiers)
변수와 문장이 뒤따릅니다.
전칭 양화사 (Universal Quantifier): 변수의 모든 값에 대해 문장이 참임을 나타냅니다.
예: ∀X likes(X, ice_cream)
존재 양화사 (Existential Quantifier): 도메인 내 일부 값에 대해 문장이 참임을 나타냅니다.
예: ∃Y friends(Y, peter)
Predicate Calculus Sentences
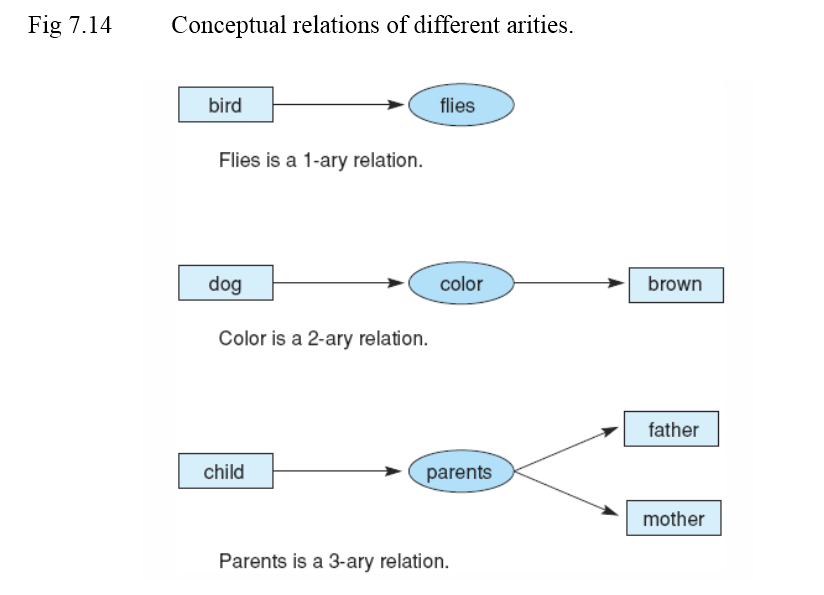
모든 원자 문장은 문장입니다.
그림 1-1
Well-formed Predicate Calculus Sentences
함수 기호: times와 plus는 아리티 2의 함수 기호입니다.
술어 기호: equal은 아리티 2, foo는 아리티 3의 술어 기호입니다.
예시:
plus(two, three)는 함수이며 원자 문장이 아닙니다.
equal(plus(two, three), five)는 원자 문장입니다.
∃X foo(X, two, plus(two, three)) ∧ equal(plus(two, three), five)는 두 결합이 모두 문장이므로 전체가 문장입니다.
(foo(two, two, plus(two, three)) → (equal(plus(three, two), five) ≡ true))는 모든 구성 요소가 논리 연산자로 적절히 연결되어 있어 전체가 문장입니다.
* Predicate Calculus의 의미론
WFF의 의미: 담론 영역의 어떤 주장
영역 (Domain): 비어 있지 않은 집합 (무한일 수 있음)
예: 정수의 집합, 가능한 8-퀸 문제의 모든 구성 집합
함수: 영역 간의 매핑
*일차 술어 논리
특징:
양화된 변수는 담론의 객체를 참조할 수 있으며, 술어나 함수는 참조할 수 없습니다.
술어는 술어로만 나타날 수 있으며, 그 자체에 대해 아무것도 주장할 수 없습니다.
예시로 제시된 표현은 일차 술어 논리에서 잘못된 형식입니다:
∀(likes)likes(george,kate).
해결 방법:
해결은 일차 논리에서만 정의됩니다.
*predicate Calculus 사용 예제
성경의 가계도를 통해 가족 관계를 설명
mother(eve, abel), mother(eve, cain)
father(adam, abel), father(adam, cain)
모든 X, Y에 대해 father(X, Y) ∨ mother(X, Y) → parent(X, Y)
모든 X, Y, Z에 대해 parent(X, Y) ∧ parent(X, Z) → sibling(Y, Z)
sibling(cain, abel)을 확인하는 예제
파일 이름: "family1.pl"
가족 관계를 정의하는 Prolog 코드
부모 관계 정의: parent(X, Y) :- father(X, Y); mother(X, Y).
다름을 확인하는 규칙: different(X, Y) :- X = Y, !, fail ; true.
형제 관계 정의: sibling(Y, Z) :- parent(X, Y), parent(X, Z), different(Y,Z).
If it doesn’t rain tomorrow, Tom will go to the mountain.
논리식: ¬weather(rain, tomorrow) → go(tom, mountain)
해석: 내일 비가 오지 않으면, 톰은 산에 갈 것이다.
Emma is a Doberman and a good dog.
논리식: gooddog(emma) ∧ isa(emma, doberman)
해석: 엠마는 도베르만이며 좋은 개이다.
All basketball players are tall.
논리식: ∀X (basketball_player(X) → tall(X))
해석: 모든 농구 선수는 키가 크다.
Some people like anchovies.
논리식: ∃X (person(X) ∧ likes(X, anchovies))
해석: 어떤 사람들은 멸치를 좋아한다.
Nobody likes taxes.
논리식: ¬∃X likes(X, taxes)
해석: 아무도 세금을 좋아하지 않는다.
*Logical Inference
표기법 "X F S": X가 S로부터 논리적으로 따라온다는 의미
X는 S를 만족하는 모든 해석에 대해 참이다.
이는 X가 S로부터 유도되거나, S로부터 유도 가능하다는 것을 의미하지 않는다.
모든 해석을 시도하는 것은 비실용적:
Inference rules는 한 표현이 다른 표현으로부터 논리적으로 따라오는지를 결정하는 계산적으로 실용적인 방법을 제공한다.
"논리적으로 따른다"는 개념:
추론 규칙의 타당성과 정확성을 증명하기 위한 형식적 기초를 제공한다.
새로운 올바른 표현을 추론: 명제나 공리 집합에서 새로운 올바른 표현을 도출하는 과정
추론 규칙: 주어진 문장에서 새로운 술어 논리 문장을 기계적으로 생성하는 방법
구문적 주장에 기반
추론 규칙의 예시:
Modus Ponens (긍정 논법): "P → Q"와 "P"가 주어졌을 때 "Q"를 얻음
Resolution
Modus Tollens (부정 논법): "P → Q"와 "¬Q"가 주어졌을 때 "¬P"를 얻음
*Inference Rule(추론 규칙): Sound, Complete
술어 논리의 의미론:
논리적 추론의 형식 이론을 위한 기초를 제공합니다.
참된 명제 집합으로부터 새로운 올바른 명제를 추론하는 능력을 강조합니다.
올바른 명제는 원래 표현 집합의 모든 이전 해석과 일치해야 합니다.
비공식 정의:
문장을 참으로 만드는 해석은 그 문장을 만족한다고 합니다.
표현 X가 술어 논리 표현 집합 S로부터 논리적으로 따라온다고 할 때, S를 만족하는 모든 해석이 X도 만족해야 합니다.
Sound (타당성):
어떤 추론 규칙이 논리 표현의 집합 S에서 작동하여 생성된 모든 문장 X가 S로부터 논리적으로 따라올 때, 그 추론 규칙은 타당하다고 합니다.
타당한 추론 규칙의 예시로 Modus Ponens와 Resolution이 있습니다.
예시로 "토끼는 눈이 좋다, 토끼는 당근을 먹는다"에서 "당근을 먹으면 눈이 좋아진다"는 귀납적 추론으로, 타당하지 않을 수 있습니다.
Complete (완전성):
추론 규칙이 S로부터 논리적으로 따라오는 모든 표현을 생성할 수 있다면, 그것은 완전하다고 합니다.
완전성은 덜 중요하지만 종종 바람직한 특성입니다.
*Useful Inference Rules(그림)
*Modus Ponens("P"와 "P→Q"가 주어졌을 때 "Q"를 추론할 수 있다는 논리 규칙)
간단한 예시:
"비가 오면 땅이 젖는다"라는 조건과 "비가 온다"는 사실이 있을 때, 우리는 "땅이 젖는다"는 결론을 도출할 수 있습니다.
여기서:
P: "비가 온다"
Q: "땅이 젖는다"
공리 집합: {P→Q, P}
*Undecidability
전제 논리의 완전성 증명은 결정 불가능합니다.
이는 변수의 무한 가능성 때문입니다.
유효성을 증명하는 절차는 존재하지만 무효성을 보일 수는 없습니다.
이는 반결정적(semi-decidable)입니다.
이러한 과정은 해결 반박 과정이라고 불립니다.
*Finding Proof(사진)
*Clause Form(논리적 일치 및 추론 과정에서 편리한 형식-함축, 전칭 및 존재 한정자가 없고 괄호가 없는 형태로, 일련의 논리합으로 구성)
변환 과정 (WFFs를 절 형태로 변환):
함축 기호 제거(Eliminate implication sign)
부정 기호의 범위 축소(Reduce scope of negation sign)
변수 표준화(Standardize variables)
존재 한정자 제거(Eliminate existential quantifier)
전항형(prenex form)으로 변환(Convert to prenex form)
행렬을 합동적 정상형(conjunctive normal form)으로 변환(Put matrix in conjunctive normal form)
전칭 한정자 제거(eliminate universal quantifier)
논리곱 제거(eliminate conjunctives)
*Requirements of Unification :
변수의 제한:
변수를 해당 변수를 포함하는 항(term)과 통합할 수 없습니다.
예를 들어, X는 f(X)로 대체될 수 없습니다
*Proof Procedure : 추론 규칙과 그 규칙을 논리적 표현 집합에 적용하여 새로운 문장을 생성하는 알고리즘의 조합입니다.
Truth Table Method:
변수를 포함하지 않는 표현의 타당성을 테스트하는 데 사용될 수 있습니다.
변수를 포함하는 표현의 타당성을 결정하는 것은 항상 가능하지 않습니다.
Complete Proof Procedure:
표현 집합에서 논리적으로 따라오는 모든 표현을 생성할 수 있습니다.
*Control of Resolution
-Derivation Graph:
어떤 해를 선택했는지를 추적하기 위한 그래프
초기 노드: 주어진 S의 절
새로운 노드: 해
링크: 부모 절에서 해로 연결
-Refutation Tree:
파생 그래프의 부분 그래프로, NIL로 레이블된 루트 노드를 가짐
집합 S가 만족 불가능함을 보여주는 해의 순서를 나타냄
*Control Strategy(Refutation Tree의 탐색 제어: 파생 그래프 내에서 반박 트리를 제어하는 방법)
완전성과 효율성:
너비 우선 검색 (Breadth-First Search):
낮은 레벨을 먼저 탐색
완전하지만 효율적이지 않음
Set-of-Support 전략:
적어도 하나는 부정된 목표 절이거나 부정된 목표로부터 생성된 절이어야 함
큰 절 공간에서 우수한 전략
Unit-Preference 전략:
Set-of-support와 단일 리터럴 우선
Linear-Input Form 전략:
부정된 목표와 원래 공리를 직접 사용
완전한 전략은 아님
**Logical Inference 예제
명제: "모든 X에 대해, 만약 X가 인간이라면, X는 필멸자이다."
해석: 소크라테스가 인간임을 나타냄.
논리적 추론: 주어진 명제와 해석에 따라, 소크라테스가 필멸자라는 결론이 도출됨.
*Mean of 'Logically Follows':S를 만족시키는 모든 해석과 변수 할당이 X도 만족시킬 때, X는 S로부터 논리적으로 따라온다고 합니다
명제 S: 모든 X에 대해, 만약 X가 인간이라면 X는 필멸자이다.
해석 I: 소크라테스가 인간임을 나타냄.
추론 X: 소크라테스가 필멸자라는 결론을 도출.
*인공지능(Artificail intelligence)
공학적 정의 :
-사람이 수행햇을 때 지능을 필요로 하는 일을 기계에게 시키고자 하는 학문/기술
-컴퓨터를 좀 더 똑똑하게 하고자 하는 연구/기술
-생각하는 기계를 만드는 연구/기술
심리학, 인지과학적 정의
-계산기법을 통하여 지능을 공부하는 것
-프로그램된 인간의 지능
*튜링 테스트(Turing Test)
튜링 테스트는 지능이 있다고 주장되는 기계의 성능을 인간과 비교하여 측정합니다.
*중요한 특징은 다음과 같습니다:
지능에 대한 객관적인 개념을 제공합니다.
혼란스럽고 답할 수 없는 질문에 휘말리지 않도록 합니다.
생명체에 대한 편견을 제거하고 기계와 공정하게 비교합니다.
*지능 시스템 : 인식, 이해, 판단, 의사결정을 포함합니다. => 이러한 시스템의 결과로 융통성, 자동화, 최적화가 이루어집니다.
*지능 시스템 개발 방법론
지식 기반 접근법(Knowledge-Based Approach) : 인간 지식을 기호 조합으로 표현, 지식 획득, 논리, 전문가 시스템, 퍼지 시스템 활용
데이터 기반 접근법(Data Driven Approach) : 수집된 예제에서 공통 특성 추출, 훈련, 통계적 방법, 인공 신경망 사용
*Generality vs. Power.
강력하고 일반적인 문제 해결사를 목표로
General Problem Solver (일반 문제 해결사)
초기의 시도 실패: 복잡성 때문에 초기 시도가 실패함.
Toy Problems Only: 단순한 이론적 문제에만 효과적임.
Power를 얻기 위해 Specialized Approach로 전환
Knowledge-Based Approach (지식 기반 접근법)
실용적인 전문가 시스템 (Expert Systems): 특정 과제를 해결하기 위해 전문가의 지식을 활용하는 실용적인 시스템.
* Biological and Social Models of Intelligence
Traditional Approach (전통적 접근법)
지식을 표현하는 방법으로 논리에 의존
주된 메커니즘으로 논리적 추론 사용
Alternative Approaches (대안적 접근법)
연결주의 네트워크 (Connectionist Networks)
인공 생명 및 유전 알고리즘 (Artificial Life and Genetic Algorithms)
에이전트 기반 문제 해결 (Agent-Oriented Problem Solving)
* Agent-Oriented Problem Solving:에이전트 지향 문제 해결은 여러 에이전트가 상호작용하여 지능적인 작업을 수행한다고 봅니다
동기 (Motivation)
사회 시스템은 지능의 또 다른 비유를 제공합니다.
개별 구성원이 해결하기 어려운 문제를 전체 시스템이 해결할 수 있는 글로벌 행동을 보입니다.
예시 (e.g.)
뉴욕시에서 하루에 소비될 빵의 양을 정확히 예측할 수는 없지만, 뉴욕의 제빵 시스템 전체가 최소한의 낭비로 도시를 잘 공급합니다.
주식 시장은 각 투자자가 제한된 정보를 가지고 있음에도 불구하고 수백 개 회사의 가치를 잘 설정합니다.
두 가지 주제
*지능을 문화와 사회에 뿌리를 둔 관점
*다수의 간단하고 상호작용하는 반자율적인 개인이나 에이전트의 집합적 행동을 통해 지능이 반영됨
에이전트 지향 및 창발적 지능의 주요 주제
에이전트의 특성
자율적 또는 반자율적
"상황에 맞게" 배치됨
상호작용적
구조화된 사회를 형성
창발적인 지능 현상을 보여줌
창발적 진화 (Emergent Evolution)
기존 요소의 예기할 수 없는 재편성으로 새로운 생물이나 행동 양식, 의식이 출현
에이전트 정의 및 설계 요건
에이전트 정의
환경의 일부 측면을 인식하고 그 환경에 영향을 미치는 사회의 요소
설계 및 구축 요건
정보 표현 구조
대안 해결책 탐색 전략
에이전트 상호작용을 지원하는 아키텍처 생성
*딥러닝(Deep Learning)
개념
딥러닝은 데이터 표현 학습에 기반한 기계 학습 방법의 일종으로, 특정 작업 알고리즘과는 다릅니다.
2006년 Geoff Hinton 등은 여러 층으로 구성된 신경망을 효과적으로 사전 훈련할 수 있는 방법을 제시했습니다.
적용 분야
컴퓨터 비전, 음성 인식, 자연어 처리, 오디오 인식 등 다양한 분야에 활용됩니다.
이러한 시스템은 인간 전문가 수준의 성능을 보이기도 합니다.
*Machine Learning vs Deep Learning
기계 학습 (Machine Learning)
입력 데이터를 특징 추출 후 분류하여 결과를 도출합니다.
사람이 직접 특징을 추출하는 과정이 필요합니다.
딥러닝 (Deep Learning)
입력 데이터를 자동으로 특징 추출 및 분류하여 결과를 도출합니다.
여러 층의 신경망을 통해 자동화된 특징 학습이 이루어집니다.
*Simple Neural Network vs Deep Learning Neural Network
단순 신경망 (Simple Neural Network)
입력층, 은닉층, 출력층으로 구성되며, 은닉층이 비교적 적습니다.
딥러닝 신경망 (Deep Learning Neural Network)
여러 개의 은닉층을 가지며, 복잡한 패턴 인식에 유리합니다.
*기계 학습(Machine Learning)
: 경험에 의하여 기계 스스로 지식을 축척하여 성능을 향상
*탐색 기법
최적화 기법
발생할 수 있는 여러 경우를 분석하여 최선의 경로를 찾는 문제 풀이 기법
기하급수적으로 증가하는 계산 복잡도의 처리 필요
가능성 있는 것부터 평가 (Heuristic Search)
국부적 정보를 이용 (Hill Climbing Method)
최적해 v.s. 적당히 좋은 해
병렬 탐색
Genetic Algorithm, Simulated Annealing
*Automated Reasoning
Qualitative Reasoning
정성적인 지식을 이용한 판단
예) 가격이 오르면 수요가 떨어진다.
Non-monotonic Reasoning
Birds can fly & Ostrich is a bird => Ostrich can fly <=> Ostrich cannot fly
Plausible Reasoning
불확실성하에서의 상충되는 정보의 융합 판단
Case-based Reasoning
경험을 근거로 한 판단
*인공신경망 (Artificial Neural Networks)
생물 신경세포의 계산 모델
뉴런 (Neuron): 단순한 기능을 수행하는 처리 요소로, 합(sum)과 비선형 임계값(non-linear thresholding)을 사용합니다.
여러 뉴런이 상호 연결되어 네트워크를 형성합니다.
학습을 통해 연결 강도(weight)를 조정합니다.
구조
연상 메모리 - 주소 지정 가능한 콘텐츠
고도의 병렬성
입력, 처리, 출력의 단계로 구성된 단순 계산 요소로 설명됩니다.
입력 링크를 통해 정보를 받아들이고, 활성화 함수(activation function)를 통해 출력을 생성합니다.
* Physical Symbol System Hypothesis : 지식의 표현과 탐색의 중요성을 강조
지능적 활동의 구성 요소
기호 패턴: 문제 영역의 중요한 측면을 표현.
연산: 이러한 패턴을 사용하여 잠재적인 해결책 생성.
탐색: 가능한 해결책 중 하나를 선택.
*Knowledge Representation
실수의 다양한 표현
실수: π
소수 표현: 3.1415927...
부동 소수점 표현: 31416 \times 10^1 (지수와 가수로 나뉨)
염색체의 디지털 이미지
배열이 자연스러운 표현 방식
술어 논리와 같은 다른 표현 방식은 번거로움
사진 2: Knowledge Representation (2)
표현 체계의 요구 사항
필요한 모든 정보를 충분히 표현할 수 있어야 함
결과 코드의 효율적인 실행을 지원해야 함
필요한 지식을 자연스럽게 표현할 수 있는 체계 제공
*AI Representation Language(AI 표현 언어)
필수 조건:
질적 지식 처리: 질적 데이터를 효과적으로 다룰 수 있어야 합니다.
추론 능력: 사실과 규칙의 집합으로부터 새로운 지식을 추론할 수 있어야 합니다.
일반 원칙 및 특정 상황 표현: 일반적인 원칙뿐만 아니라 특정 상황도 표현할 수 있어야 합니다.
복잡한 의미 포착: 복잡한 의미론적 의미를 포착할 수 있어야 합니다.
메타 수준의 추론 허용: 메타 수준의 추론을 허용해야 합니다.
질적 지식 처리:
블록 세계와 같은 예시를 통해 질적 지식을 다룰 수 있어야 합니다.
술어 논리를 사용하여 설명 정보를 직접 캡처합니다
새로운 지식 추론:
사실과 규칙의 집합으로부터 새로운 지식을 추론할 수 있어야 합니다.
예시: 모든 X에 대해, Y가 X 위에 존재하지 않으면 X는 비어 있음.
논리 표현: ∀X,¬∃Yon(Y,X)⇒clear(X)
*AI 표현 언어의 요구 사항
질적 지식 처리: 복잡한 상황을 다룰 수 있어야 합니다.
새로운 지식 추론: 사실과 규칙으로부터 새로운 정보를 도출할 수 있어야 합니다.
일반 원칙 및 특정 상황 표현: 변수 사용을 통해 일반적인 원칙과 특정 상황 모두를 표현할 수 있어야 합니다.
복잡한 의미 포착: 복잡한 의미론적 의미를 효과적으로 표현해야 합니다.
메타 수준의 추론 허용: 메타 수준에서의 추론을 지원해야 합니다.
복잡한 의미 포착:
대량의 구조화된 상호 연관 지식이 필요합니다.
논리적 술어 집합을 사용하여 다양한 속성을 표현합니다.
메타 수준 추론 허용:
지능형 시스템은 문제 해결 능력뿐만 아니라 자신이 알고 있는 것을 이해하고 설명할 수 있어야 합니다.
지식을 구체적이고 일반적인 용어로 설명할 수 있어야 합니다.
메타 지식:
자신이 알고 있는 것에 대한 인식을 포함합니다.
진정한 지능형 시스템 설계 및 개발에 필수적입니다.
AI 표현 언어:
술어 논리, 의미 네트워크, 프레임 및 객체를 포함합니다.
구현 언어로 LISP와 PROLOG가 사용됩니다.
* ER 모델링에서 엔티티란 무엇이고 엔티티를 구성하는 애트리뷰트의 종류에는 무엇이 있을까요?
엔티티 : 실세계에서 독립적으로 존재하는 실체
애트리뷰트 유형
복합 애트리뷰트(Composite) : 애트리뷰투의 집합
단순 애트리뷰트(Simple) : 원자 애트리뷰트
단일 값 애트리뷰트(Single value) : 애트리뷰트 하나는 하나의 값을 가짐
다치 애트리뷰트(Multi-valued) : 애트리뷰트 하나가 여러 값을 가질 수 있음
저장된 애트리뷰트(Stored) : DB에 실제로 저장된 애트리뷰트
유도된 애트리뷰트(Derived) : 실제 저장되어 있지 않음(다른 애트리뷰트에 의해 그 값이 유도될 수 잇는 애트리뷰트)
* 밑줄 친 애트리뷰트는 무엇을 의미하나요? 이러한 애트리뷰트가 가져야 하는 특징이 무엇일까요?
키 애트리뷰트 : 각 엔티티마다 서로 다른 값을 가지는 애트리뷰트
* 이진 관계(Binary relationship)는 몇 개 엔티티 간의 관계를 나타낼까요? - 2개
* 그리고 이러한 이진 관계에는 1:1, 1:N, M:N의 카디날리티 비율이 있을 수 있는데, 그 의미를 설명하고 각각에 대한 예제를 들 수 있나요?
*개체, 개체 집합, 애트리뷰트, 키
ER 모델 : 엔티티(실세계에서 독립적으로 존재하는 실체) - 관계 - 속성(애트리뷰트)(엔티티를 기술하는 속성)
NULL 값 : 적용할 수 없음이라는 의미, 알려지지 않음의 의미
*관계 모델에서 삭제 연산은 참조 무결성 제약 조건을 위반할 수 있습니다. 어떠한 경우에 참조 무결성 제약 조건이 위반되는지 설명할 수 있나요? 이러한 위반이 발생할 경우에 취할 수 있는세 가지 옵션은 무엇일까요
부모 테이블에서 튜플을 삭제할때 이를 참조하는 자식 테이블의 외래키가 존재할때 참조 무결성 제약조건을 위반한다.
-삭제를 거부
-삭제되는 투플을 참조하는 투플들까지 모두 삭제(연쇄 삭제)
-삭제되는 투플을 참조하는 투플들에서 외래키 값을 널로 바꾸거나 다른 유효한 투플을 참조하도록 변경
*도메인 : 애트리뷰트가 가질수 잇는 원자값들의 집함(eX : 15~80사이의 사원들의 나이)
*데이터 타입 : 도메인은 실제 데이터 타입으로 명시함
*릴레이션 스키마 : 릴레이션 이름 R과 애트리뷰트 A들의 집합으로 표기함
릴레이션의 차수 : 릴레이션의 애트리뷰트 개수(STUDENT(Name, SSN, BirthDate, Address) 릴레이션의 차수 = 4)
릴레이션의 특성
1.릴레이션에서의 투플의 순서(순서,중복 중요 x) : 집합에서 원소의 순서가 무의미한 것과 마찬가지로 투플의 순서 역시 의미가 없음
*관계 모델 제약 조건
1. 도메인 제약 조건 : 속성 값은 도메인에 속해야함
- 각 애트리뷰트 A의 값은 반드시 A의도메인 domain(A)에속하는 원자값이어야 함
2. 키 제약 조건 : 모든 튜플은 유일해야 함
-릴레이션은 투플의 집합으로 정의되므로, 모든 원소는 중복되어서는 안됨
-기본키
3. NULL에 대한 제약 조건 : NULL이 허용되지 않은 경우 NULL이면 안됌
-애트리뷰트 값으로 널을 허용하지 않는 경우, 애트리뷰트는 널을 가질 수 없음
4. 엔티티 무결성 제약 조건 : 기본키가 NULL일수없음
-기본키가 각 투플들을 식별하는 데 이용되기 때문에 어떠한 기본 키 값도 널 값을 가질 수 없다는 제약 조건임, 기본키 릴레이션의 속성을 정의할 때 not null임을 명시
5. 참조 무결성 제약 조건 : 두 릴레이션 간 기본키-외래키 참조 관계를 나타냄
-한 릴레이션에 있는 투플이 다른 릴레이션에 있는 투플을 참조하려면 반드시 참조되는 투플이 그 릴레이션 내에 존재해야 함
*삭제 연산이 참조 무결성 제약조건을 위반하는 경우 취할 수 있는 세가지 옵션
-삭제를 거부
-삭제되는 투플을 참조하는 투플들까지 모두 삭제(연쇄 삭제)
-삭제되는 투플을 참조하는 투플들에서 외래키 값을 널로 바꾸거나 다른 유효한 투플을 참조하도록 변경
1.SQL에서 문자열 애트리뷰트를 나타내는 CHAR(n)과 VARCHAR(n)은 어떤 차이가 있을까요?
char은 고정길이 문자열이고 varchar은 가변길이 문자열이다.
2.테이블을 생성하는 다음 CREATE TABLE 구문을 설명할 수 있나요? NOT NULL, PRIMARY KEY 등의 의미가 무엇일까요
NOT NULL : NULL을 허용하지 않는다, PRIMARY KEY : 기본키로 지정한다(유니크(중복을 허용하지않는다)
*동일한 이름을 갖는 애트리뷰트의 사용하는 경우
-서로 다른 릴레이션에서 동일한 이름을 갖는 애트리뷰트가 사용될 수 있음
-릴레이션 이름과 함께 애트리뷰트 이름을 사용함으로써 모호함을 방지해야 함
*동일한 릴레이션을 두 번 참조하는 경우
- 릴레이션 이름의 별명을 애트리뷰트 이름 앞에 붙여서 사용
*Generalized Forwarding(목적지 기반 포워딩)
라우터의 포워딩 테이블: 각 라우터는 포워딩 테이블(또는 플로우 테이블)을 가지고 있습니다.
이 테이블은 패킷을 어떻게 처리할지 결정하는 데 사용됩니다.
"매치 플러스 액션" 추상화:
도착한 패킷의 비트를 매칭하여 적절한 행동을 취합니다.
일반화된 포워딩에서는 여러 헤더 필드가 행동을 결정할 수 있습니다.
가능한 여러 행동:
패킷을 드롭(drop)
복사(copy)
수정(modify)
로그(log) 기록
*middleboxes: 네트워크 경로 상에서 일반적인 IP 라우터의 기능 외에 다른 기능을 수행하는 중간 장치
기능: 일반적인 라우터의 역할을 넘어서는 기능을 수행합니다.
위치: 네트워크 경로의 중간에 위치하여 데이터 흐름을 제어하거나 수정할 수 있습니다.
예시: 방화벽, NAT(Network Address Translation) 장치, 로드 밸런서 등이 있습니다.
*네트워크에서 다양한 중간 장치(Middlebox)의 역할과 위치
NAT (Network Address Translation): 가정, 셀룰러, 기관 네트워크에서 사용됩니다. IP 주소를 변환하여 네트워크 트래픽을 관리합니다.
Application-specific Middleboxes: 서비스 제공자, 기관, CDN(Content Delivery Network)에서 사용되며, 특정 애플리케이션의 요구에 맞춘 기능을 제공합니다.
Firewalls 및 IDS (Intrusion Detection Systems): 기업, 기관, 서비스 제공자 및 ISP에서 사용됩니다. 네트워크 보안을 강화하고 침입을 탐지합니다.
Load Balancers: 기업, 서비스 제공자, 데이터 센터 및 모바일 네트워크에서 사용됩니다. 트래픽을 여러 서버에 분산시켜 성능과 안정성을 향상시킵니다.
Caches: 서비스 제공자, 모바일 네트워크, CDN에서 사용되며, 데이터를 임시 저장하여 접근 속도를 높입니다
*SDN 및 NFV
왼쪽:
전통적 네트워크 구조:
L3 코어 스위치와 여러 방화벽(F/W)이 로비, 응급실, 수술실 등의 다양한 네트워크 구역에 배치되어 있습니다.
각 구역에 대해 개별적으로 방화벽이 설치되어 있어, 물리적 장비가 많이 필요합니다.
오른쪽:
SDN 및 NFV를 활용한 구조:
OpenFlow 컨트롤러: 중앙에서 네트워크 트래픽을 제어하고 관리합니다.
방화벽 풀(F/W pool): 물리적 방화벽 대신 가상화된 방화벽을 사용하여 유연성을 제공합니다.
서버 풀과 풀 메쉬 네트워크: 다양한 네트워크 장비와 서버가 가상화된 환경에서 효율적으로 연결됩니다.
OpenFlow 스위치: 각 층에 배치되어 중앙 컨트롤러와 통신하며, 네트워크 트래픽을 효과적으로 관리합니다.